
{kind=link}
Reading and understanding philosophical texts is often seen as a task that requires rationality, higher order thinking, and abstract reasoning. This seems like something that humans are uniquely able to do, and if we encountered a new species, and they could do philosophy, it would be hard to deny their rationality. It is one thing if a monkey, a parrot, or a smart phone can do basic math, but another if they can offer commentary on Plato. In this post we will look at how an artificial intelligence system, (specifically Latent Dirichlet Allocation Topic Modelling with Gibbs Sampling) would categorize Plato’s dialogues. The system won’t be trying to do anything too complicated, just divide the dialogues into categories that make sense with minimal human input. Surprisingly the program does identify clear topics in the works of Plato, though they are not the topics I initially hypothesized.
Hypothesis
My initial plan when starting this project was to test if a Topic Modeling system would successfully identify and sort dialogues into Plato’s Early, Middle, and Late period. This theory of Plato divides his works into three main periods, the early period consisting of dialogues that do not put forward positive views, and are mostly considered to simply document the thoughts of Socrates, his middle period where dialogues get more complex and he starts to put forward some of his own views, and the late period which has stylistic changes and potentially a maturing of his position. This theory is hotly debated, and it would be interesting either if machine learning systems supported it, or did not. For a refresher on this theory, check out this video.
Methods
In layman’s terms, topic modeling looks at a group of texts and tries to find topics, or groups of words that fit together. Each topic is comprised of words, with each word ranked by its probability of being in that topic. Each document is then comprised of topics, with each topic ranked by the probability of being in that document. The only things that are provided to the system by a human are the number of topics in a document and a set of “stop words” which should not be used to create topics (often words that are common to all documents, like “the” or “a”, but also words that might appear throughout a particular collection of documents. For a primer on Topic Modeling for philosophy, check out the video below.
In order to do this, we need the complete works of Plato in separate text files. For this experiment, I use the versions available in Project Gutenberg’s free library of e-Books (the Benjamin Jowett translation with the introductory and metadata removed). As these are an English translation they may miss some of the stylistic nuance of the original Greek, and perhaps in the future we will try this same experiment with the original language texts. For stopwords I include many of the names used in the dialogues (as these are very common to many dialogues and therefore confuse the system) and words that appear throughout, such as affirmative responses to Socrates. The specific topic modeling package used was created for AI research in the humanities and the arts by DARIAH-DE, a German institute for using Digital technologies to study the arts and humanities. See below for citations and the code used.
Results
Based on this, I first set out to see if the system would identify dialogues associated with early, middle, and late Plato as separate topics, or importantly different. The visualization below shows these results (for easier reading, click the “full screen” button in the corner). While the system seems to have identified a topic (Topic 1 below) that is more likely to be found in Late Plato, it does not do that much to differentiate early and middle Plato. Early Plato seems to have more of Topic 3 and Middle Plato more of topics 1 and 2, but not by much. Additionally the topics themselves seem a bit muddled. Topic 1 has some words that clearly match to political philosophy (which might make sense in late dialogues as well as some middle dialogues) such as Athenian, laws, city, order, etc. However, good and man show up fairly highly ranked in both topics 2 and 3, meaning that these topics are not doing a good job of separating out these concepts. Use the filter in the visualization to get a close up of the breakdown of each dialogue.
One solution might be to try to add more stop words. While “good” is a central concept of philosophy, it is also a very common word throughout the dialogues, making it hard for the system to identify topics based on it. However, while adding these stopwords might help address this issue, it does seem strange to speak of Plato without a central concept of ethics, and it wouldn’t explain the fact that there seem to be multiple topics mixed together (good and knowledge, law and nature etc.). Therefore I decided to go a different route and see if more sense could be made using more topics. If you want to try adding different stopwords yourself, or see which words I included, I have included the underlying code at the bottom of this blog.
The word cloud visualization below shows several other options for the number of topics that we can divide the dialogues into. First select the number of topics you think Plato should be divided into, then click on each topic to see the most common words in that topic (the larger the word, the more common in that topic). The key is to try to find a number of topics where each topic seems to contain just one concept, and all of the topics make some degree of sense.
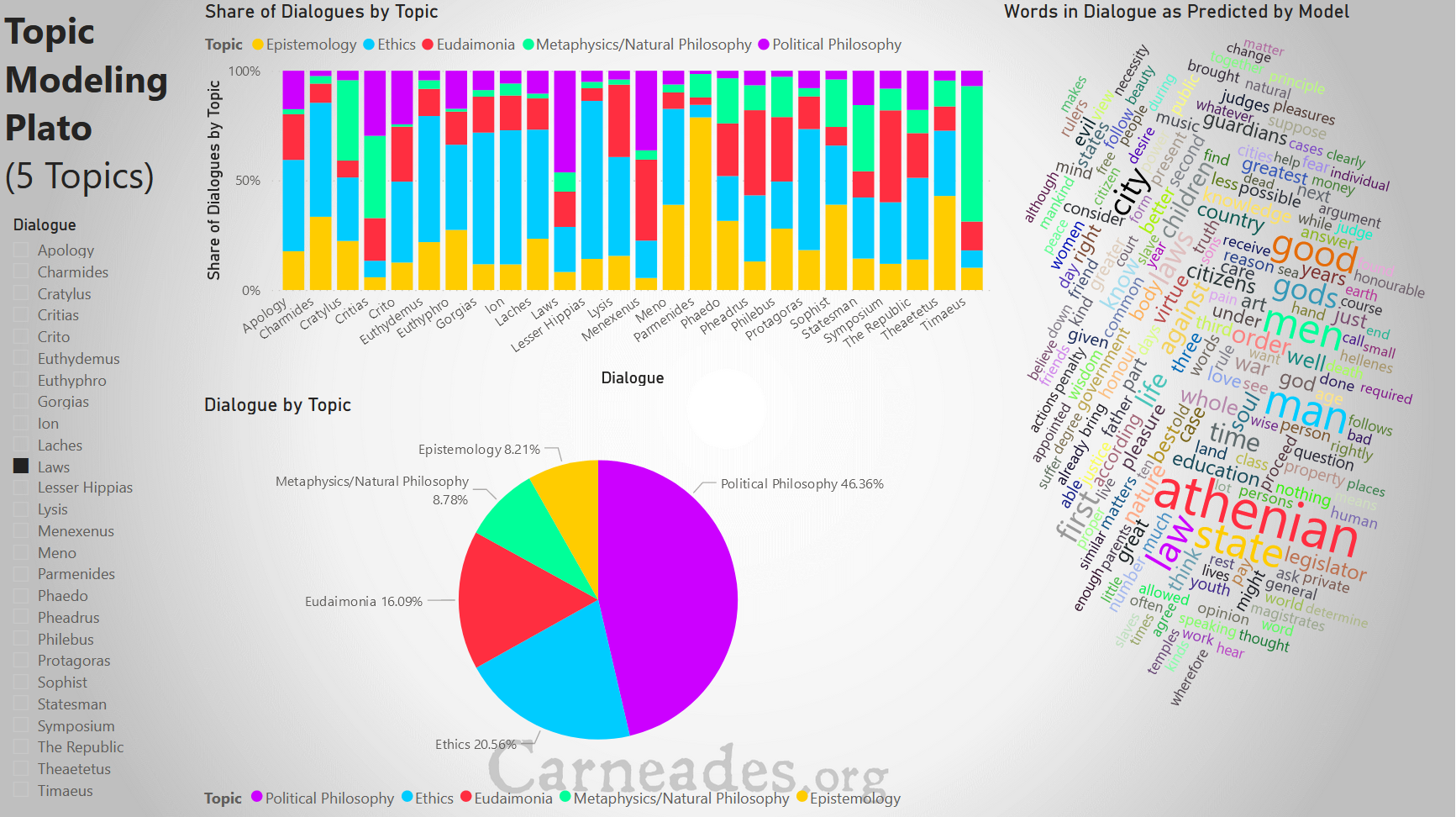
It seems to me that the best arrangement is 5 topics. Topic 1 picks out words that seem to refer to the “good life” or eudaimonia: pleasure, love, life, friends, beauty. Topic 2 is clearly focused on political philosophy, with Athenian, state, city, laws and citizens featuring prominently. Topic 3 appears geared towards epistemology, with words like knowledge, know, opinion, and argument being very common. Topic 4 seems to be a mix of metaphysics with words like body, soul, and form, and natural philosophy (i.e. science before science) with words like nature, earth, water, fire, and air. But this makes sense as the lines between these disciplines were weak if existent at all when Plato was writing. The final topic, topic 5, seems to be focused on ethics, with good, evil, justice, and just featuring prominently. Impressively, the program has divided the dialogues into what we might today consider major topics in philosophy, without being able to “understand” what is actually being said in the dialogues, or referencing any other materials.
Using these labels for our topics (Eudaimonia, Political Philosophy, Epistemology, Metaphysics/Natural Philosophy, and Ethics), we can look at how the dialogues are categorized by these topics. Some categorizations make clear sense: Laws is focused on political philosophy, Timeaus is focused on Metaphysics and Natural Philosophy, and Meno is evenly split between Ethics and Epistemology. Others are more questionable, while Parmenides has a critique of method that might fit with it being somewhat focused on Epistemology, it also has an extensive critique of the forms, which would fit better under Metaphysics, but this barely registers.
Moving to the second page of this visualization, we can see an analysis of the three periods of Plato using this new categorization. Much more than the initial analysis with only three topics, this analysis supports the early, middle, and late division of these texts. Almost all of the early texts are dominated by ethics as a concept, and almost completely exclude any mention of metaphysics, or the forms, something that non-computerized philosophers agree with. The late dialogues by contrast are much more focused on metaphysics and natural philosophy. They are also the most balanced of the dialogues, perhaps suggesting a more matured viewpoint. The middle dialogues by this analysis are more focused on epistemology and methods than any other topic, but they seem to be the most heterogeneous group, potentially providing support for the claim that this group should be further subdivided.
Conclusion
All of this may be simply reading what I want to see in the tea leaves and a sort of p-hacking by manipulating the parameters of the model until I arrive at a conclusion that makes sense, so I don’t know if this system even comes close to understanding anything about Plato, even in a Weak AI sense. However, across iterations there are certain patterns that appear, certain words the program is able to identify as consistently going together, and certain dialogues that look similar to each other. Political philosophy is almost always identified as a separate topic, words about “natural philosophy” are almost always sorted into the same topic, etc. And, at least using some sets of topics, there does appear to be a distinction between early, middle, and late Plato. It is impressive to see the system identifying topics that we might identify as areas of philosophy today, indicating that some of these may naturally flow as separate areas of study from the works of Plato. I don’t know if the program can understand any of Plato, but then again, I don’t know if I understand any of Plato either. Stay Skeptical!
Citations
Severin Simmler, Thorsten Vitt and Steffen Pielström, Topic Modeling with Interactive Visualizations in a GUI Tool, in: Proceedings of the Digital Humanities Conference (2019).
Project Gutenberg. (n.d.). Retrieved October, 2021, from www.gutenberg.org
#Python Topic Modeling Program:
from pathlib import Path
import dariah
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
path = "" #ENTER PATH
stop_WDS = ["a", "socrates", "the", "and", "you", "of", "to", "is", "that",
"he", "not", "are", "in", "said", "have", "which", "be", "we", "they", "their",
"them", "who", "one", "or", "shall", "but", "will", "as", "do", "what", "for",
"would", "say", "his", "me", "this", "by", "for", "all", "as", "let", "if", "any",
"with", "will", "it", "as", "but", "then", "there", "him", "at", "was", "my", "no",
"may", "has", "about", "when", "being", "same", "than", "other", "true", "things", "was",
"these", "our", "may", "into", "must", "so", "another", "can", "others", "like", "on",
"those", "such", "yes", "your", "only", "am", "were", "us", "now", "theaetetus",
"many", "some", "very", "again", "more", "had", "nor", "an", "how", "also", "does",
"been", "make", "most", "her", "every", "tell", "saying", "out", "called", "each",
"she", "whom", "replied", "way", "two", "young", "either", "neither", "place",
"own", "should", "ought", "hermogenes", "yet", "rather", "even", "made", "because",
"itself", "anything", "become", "callicles", "polus", "phaedrus", "give", "indeed",
"therefore", "did", "always", "could", "never", "meno", "ion", "off", "until", "go",
"upon", "over", "up", "ever", "away", "hippias", "euthyphro", "laches", "gorgias",
"far", "quite", "crito", "becomes", "its", "thus", "without", "meillus", "doing",
"agathon", "megillus", "theodorus", "nicias", "from", "whether", "cleinias",
"cannot", "thing", "having", "certainly", "stranger", "both", "still","too",
"himself", "speak", "after", "before", "themselves", "use", "why", "name", "names",
"mean", "take", "come", "among", "manner", "sort", "cratylus", "euthydemus",
"protarchus", "dionysodorus"]
topic_count = 2
while topic_count < 11:
model, vis = dariah.topics(path,stopwords=stop_WDS, num_topics=topic_count, num_iterations=1000)
print(model.topic_document.iloc[:, :26])
print(model.topic_word.iloc[:, :50])
print(model.topics.iloc[:, :15])
model.topic_document.to_csv("Topics and Texts " + str(topic_count) + ".csv")
model.topics.to_csv("Words and Topics " + str(topic_count) + ".csv")
model.topic_word.to_csv("Words and Probabilities " + str(topic_count) + ".csv")
print(topic_count)
topic_count = topic_count + 1